Hi all,
I’m having a weird issue with ICA on one of my subjects. Before I describe the problem, I want to make it clear that this exact code works fine for all of my subjects except this one. Usually, ICA results in 80 sensible components (usually two cardiac components and a number of blink/MOG components). I identify these artefactual components manually and project them out using ica.exclude and ica.apply. It generally works very well to remove blink and heartbeat artifacts (they are no longer visible in the filtered data in the raw or PSD plots).
The issue happens with a particular resting-state recording (CTF-275, 1200 Hz sampling rate, 5 minutes) from the open dataset I am looking at (Mother Of all Unification Studies, available on Donders repo.)
I first load the MEG file, broadband filter, and apply reference array gradiometry:
filepath = op.join(megpath, restdatapath)
raw = mne.io.read_raw(filepath, preload=False) # read raw data, don't load yet
raw.pick_types(meg=True, eeg=False) # get rid of EEG channels
filtered = raw.copy()
filtered.load_data()
filtered.filter(l_freq=1.0, h_freq=150.) # FIR filter from 0.1-150 Hz
filtered.apply_gradient_compensation(grade=3) # apply gradiometry
filtered_orig = filtered.copy() # make another copy for post-ICA comparison
Then do ICA with 80 components:
ica = mne.preprocessing.ICA(n_components=80, random_state=40,
method='picard', max_iter=1500)
ica.fit(filtered, decim=4) # 1200/4 = 300 Hz = 150 * 2 (Nyquist limit)
which outputs the following:
# Subject has no previous ICA. Computing...
# Fitting ICA to data using 273 channels (please be patient, this may take a while)
# Removing 5 compensators from info because not all compensation channels were picked.
# Selecting by number: 80 components
# Fitting ICA took 48.0s.
Here is a plot of the first 10 components and their respective time courses:
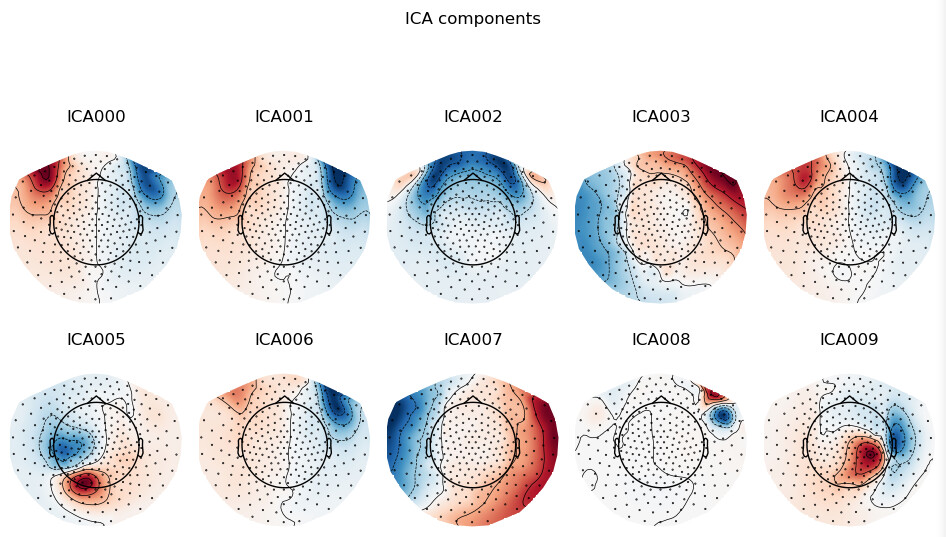

Looks relatively sensible so far. One thing I noticed about this recording in particular is that the ICA seems to pull out two EOG components (ICA000, ICA001) with very similar topography. This is stable across the different ICA implementations (infomax, picard, fastica etc.) and with different parameters (within reason). The issue occurs when I try to project out one or both of these components. I will project out ICA000 just to demonstrate:
ica.exclude=[0]
ica.apply(filtered)
This reports:
# Applying ICA to Raw instance
# Transforming to ICA space (80 components)
# Zeroing out 1 ICA component
# Projecting back using 273 PCA components
# <RawCTF | sub-A2011_task-rest_meg.meg4, 301 x 368298 (306.9 s), ~846.3 MB, data loaded>
If I then plot the PSD of the ICA-applied data next to the original, it becomes clear that something very bad has happened:

The ICA-applied data (upper plot) shows broadband noise which didn’t exist in the original (lower plot). Furthermore, this synthetic noise appears to have the topography of the ICA component we tried to project out:

Does anyone have any clue what’s happening here? Maybe some kind of numerical instability in the algorithm? Or perhaps I am being silly.
Here is my platform information: I’m using MNE version 0.22 (stable) running inside WSL2 in Windows 10. I haven’t encountered any issues like this before with MNE – as I said, this just happens with the one subject (sub-A2011 in the MOUS dataset – it’s open to download, you have to sign up to an eduID account). In all other subjects the ICA works properly, eye blinks and heartbeats are cleaned, and I can proceed with analysis.
I’d be grateful if anyone has any ideas or pointers. Thanks for reading!
Platform: Linux-5.4.72-microsoft-standard-WSL2-x86_64-with-glibc2.10
Python: 3.8.8 | packaged by conda-forge | (default, Feb 20 2021, 16:22:27) [GCC 9.3.0]
Executable: /home/neurons/miniconda3/envs/mne-sktime/bin/python
CPU: x86_64: 12 cores
Memory: 25.0 GB
mne: 0.22.0
numpy: 1.20.2 {blas=NO_ATLAS_INFO, lapack=lapack}
scipy: 1.6.2
matplotlib: 3.3.4 {backend=Qt5Agg}
sklearn: 0.24.1
numba: 0.51.2
nibabel: 3.2.1
nilearn: 0.7.1
dipy: 1.4.0
cupy: Not found
pandas: 1.2.3
mayavi: 4.7.2
pyvista: 0.29.0 {pyvistaqt=0.3.0, OpenGL 3.3 (Core Profile) Mesa 20.0.8 via llvmpipe (LLVM 10.0.0, 128 bits)}
vtk: 9.0.1
PyQt5: 5.12.3
