in one of my recent analyses I ran into some problems with regard to
morphing and single trial
label time series extraction which lead me to set up some comparisons:
(gist based on sample data, should run with a proper MNE-Python install)
[image: Inline image 1]
It turned out morphing was unproblematic, but,
I'm wondering whether the differences between averaging in source space and
projecting evokeds is expected, and if so, how it can be avoided?
The background is that I'd like to be confident about the relating single
trial analyses at the evoked level.
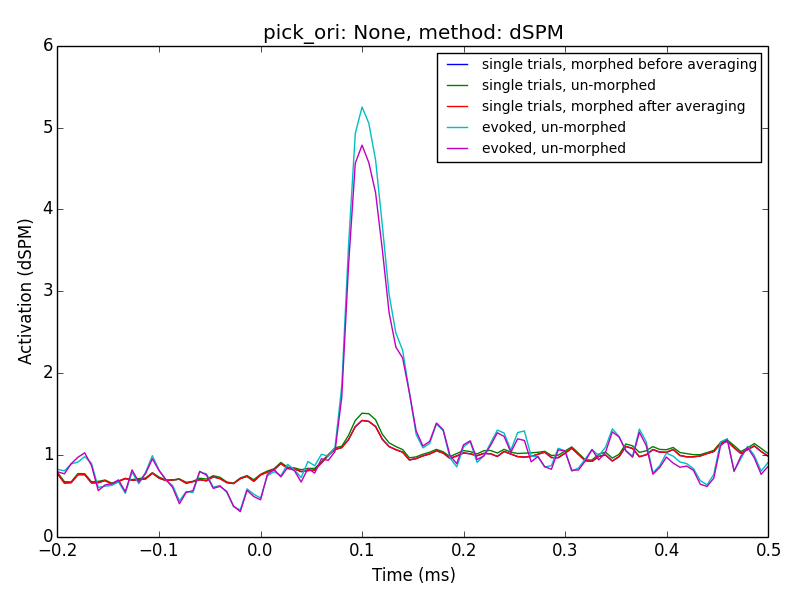
Which line represents "averaging in source space" and which represents
"projecting evokeds"?
Regardless. I think you are referring to why are the results different when
I average single trial data on the source space as opposed to averaging
that same data in sensor space and then source localizing?
The first reason I can think of is that you are using the dSPM here and I
believe that that can lead to some non-linearity between these results. Do
you get the same problem with the L2?
HTH,
D
Hi folks,
in one of my recent analyses I ran into some problems with regard to
morphing and single trial
label time series extraction which lead me to set up some comparisons:
(gist based on sample data, should run with a proper MNE-Python install)
[image: Inline image 1]
It turned out morphing was unproblematic, but,
I'm wondering whether the differences between averaging in source space and
projecting evokeds is expected, and if so, how it can be avoided?
The background is that I'd like to be confident about the relating single
trial analyses at the evoked level.
Any thoughts?
Cheers,
Denis
_______________________________________________
Mne_analysis mailing list
Mne_analysis at nmr.mgh.harvard.edu Mne_analysis Info Page
The information in this e-mail is intended only for the person to whom it
is
addressed. If you believe this e-mail was sent to you in error and the
e-mail
contains patient information, please contact the Partners Compliance
HelpLine at MyComplianceReport.com: Compliance and Ethics Reporting . If the e-mail was sent to you in
error
but does not contain patient information, please contact the sender and
properly
dispose of the e-mail.
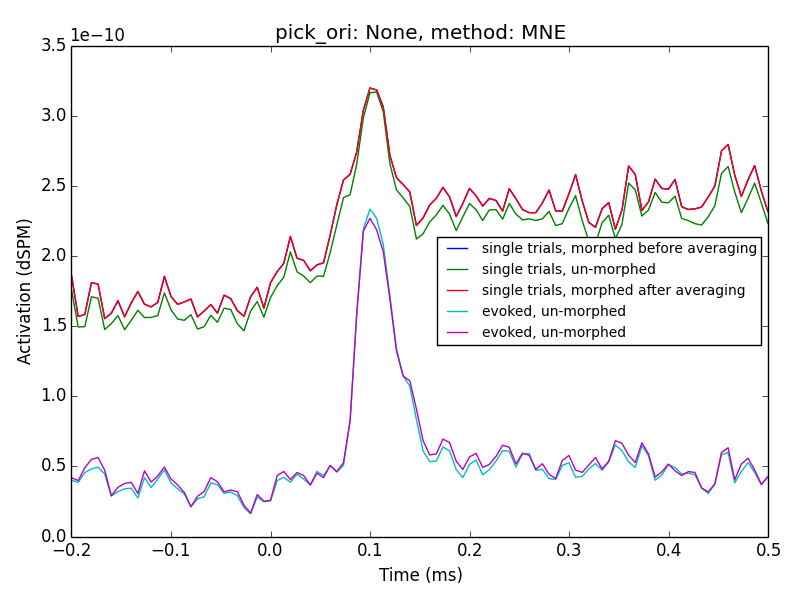
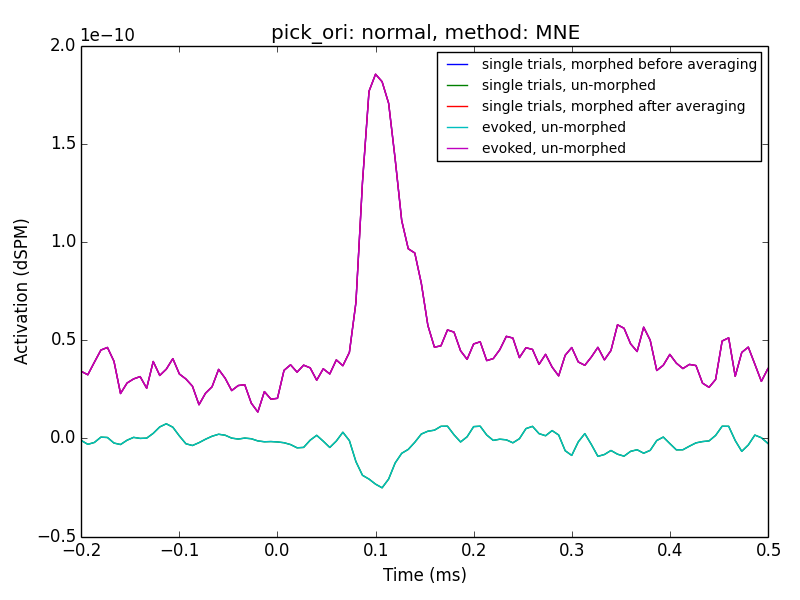
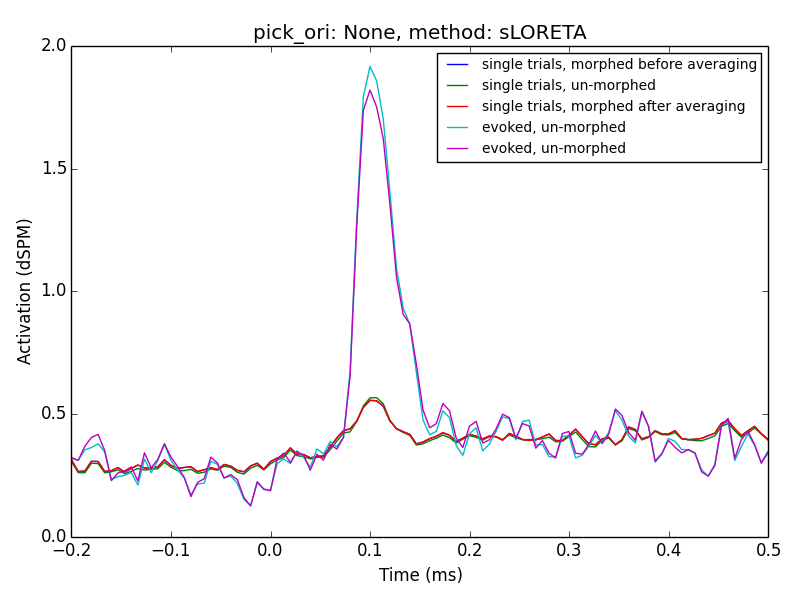
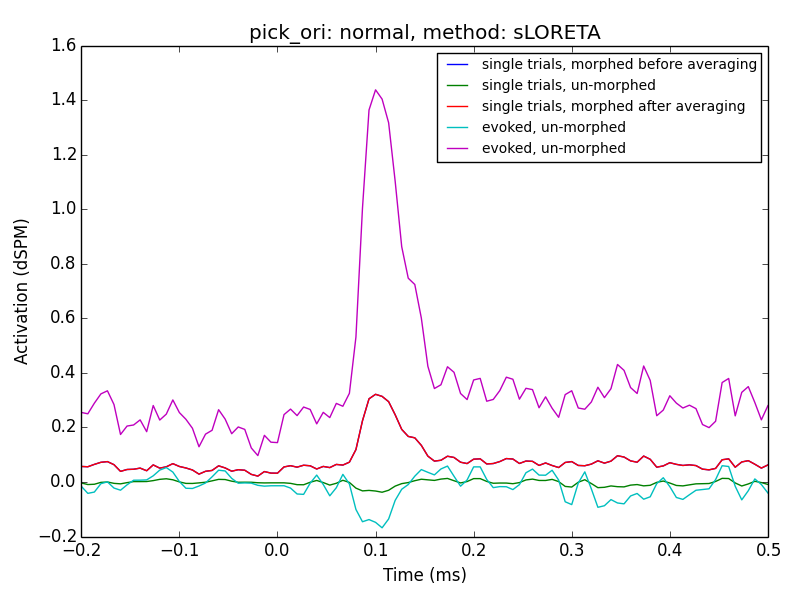
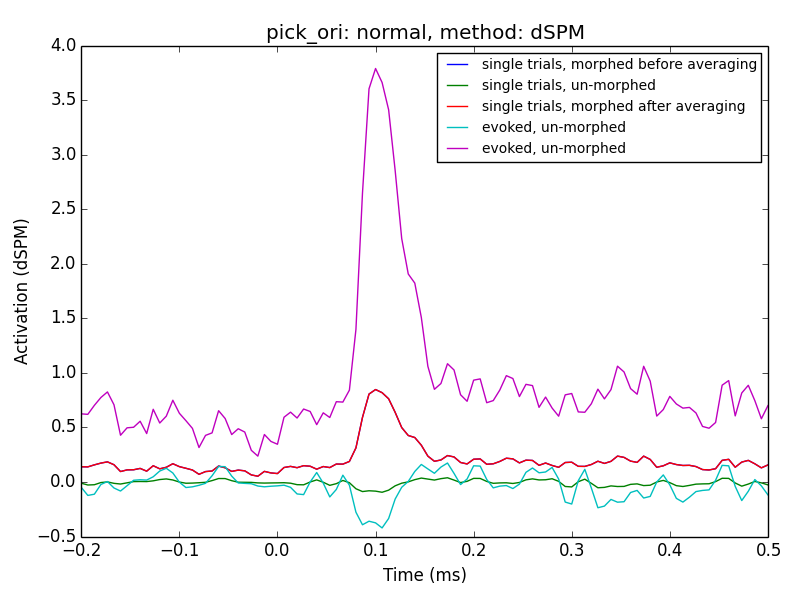
I've updated the gist to do some more systematic comparisons between
orientations and methods:
As to you clarification questions, the lines referred to in the legend as
'single*' are related to averaging in source space.
It seems using MNE and with a post-hoc normalization, e.g. using z-scores
might be the way to go.
From my ad-hoc parameter experiment I cannot exclude the possibility, that
'dSPM' and 'sLORETA' with 'normal' orientation might work as well.
This would require a mean-flip method though which is not implemented in my
script due to the manual extraction used.
My extraction function, here, was `lambda x: np.abs(x).mean(0)`
This needs more investigation + discussion
Denis
Images:
Hi Denis,
Which line represents "averaging in source space" and which represents
"projecting evokeds"?
Regardless. I think you are referring to why are the results different
when I average single trial data on the source space as opposed to
averaging that same data in sensor space and then source localizing?
The first reason I can think of is that you are using the dSPM here and I
believe that that can lead to some non-linearity between these results. Do
you get the same problem with the L2?
HTH,
D
Hi folks,
in one of my recent analyses I ran into some problems with regard to
morphing and single trial
label time series extraction which lead me to set up some comparisons:
(gist based on sample data, should run with a proper MNE-Python install)
[image: Inline image 1]
It turned out morphing was unproblematic, but,
I'm wondering whether the differences between averaging in source space
and
projecting evokeds is expected, and if so, how it can be avoided?
The background is that I'd like to be confident about the relating single
trial analyses at the evoked level.
Any thoughts?
Cheers,
Denis
_______________________________________________
Mne_analysis mailing list
Mne_analysis at nmr.mgh.harvard.edu Mne_analysis Info Page
The information in this e-mail is intended only for the person to whom it
is
addressed. If you believe this e-mail was sent to you in error and the
e-mail
contains patient information, please contact the Partners Compliance
HelpLine at MyComplianceReport.com: Compliance and Ethics Reporting . If the e-mail was sent to you
in error
but does not contain patient information, please contact the sender and
properly
dispose of the e-mail.
Your observations about post hoc normalization make sense:
When looking at a single vertex over time or frequency, MNE, dSPM,
sLORETA, etc. are just scaled versions of each other (i.e., by a constant
scalar factor).. The effect of changing 'nave' (which is what is different
between your apply_inverse and apply_inverse_epochs cases) would also only
affect the scaling factor with the time course itself intact...Thus, when
you normalize within vertex post hoc, they become the same once again..
*However*, when looking *across sources*, this constant scale factor for
each source would be different (which of course is the basis for the
improved resolution of dSPM and sLORETA over MNE).. So if you are looking
at spatial maps AND projecting single trials, it may be useful to
explicitly set nave to n_epochs even in the single trial case..
To revive this thread: Denis, in the PDF you posted, the averaged then
transformed data still looks different from the transformed then averaged
data if pick_ori is set to None. What's causing this?
Re baseline correcting, so the general recommendation when working with
single-trial data is to use MNE rather than dSPM, then normalize each epoch
individually (explicitly, subtract the mean of the baseline from the whole
epoch, then divide the whole epoch by the standard deviation of the
baseline)?
Hi Tal et al.,
Just some thoughts.. Feel free to pick them apart:
Combining the three components (rather than picking the normal component
only) using a norm calculation is a non-linear operation that changes
things and it matters whether you do normalization first or whether you
combine components first... This is related to the discussion in issue #962: https://github.com/mne-tools/mne-python/issues/962
Also, I don't think there is a good way to come with a "standard"
recommendation for single trial data which is general enough.. A lot would
depend on what the subsequent use is (and possibly processing history, eg:
what data you used to estimate the noise-covariance matrix).
That said, if you are interested in time-courses, rather than spatial
maps, then using any of the three should be OK. Indeed, for measures that
depend only on the time course and not scaling (like coherence for
example), you should get identical results for MNE/dSPM/sLORETA and
regardless of how you baseline normalize.
I personally have never used free orientation solutions (i.e., I have
always used fixed or pick=normal).. This is partly because I cannot
think of any good way to combine the components and still be able to
do spectral/time-series analyses after that. Others with more
experience here may have better insight.
Also, just wanted to quickly add that in my understanding, what dSPM is
essentially trying to achieve is the same kind of normalization as would
result when you do MNE first and then scale by the baseline.. So those
results (i.e., MNE and then normalize by baseline Vs. dSPM) should be
very similar, especially if the same baseline period is used for
calculating the noise covariance matrix.
Also, just wanted to quickly add that in my understanding, what dSPM is
essentially trying to achieve is the same kind of normalization as would
result when you do MNE first and then scale by the baseline..
it's the same objective but it's mathematically different.
one more thing to add is that the nave also plays a role
in the scaling of the regularization parameter. It scales the noise
cov used in dSPM but it's not a plain scaling
of the estimates.
Thanks. So just to make sure I understand what this all means, what is the
recommended nave value for a single trial source solution, assuming we want
to later average the single trial activations and get something similar to
applying the inverse operator to averaged epochs? And what is the
implication of what you're saying for choosing dSPM or MNE in a single
trial analysis?
Hi Alex,
Just to follow up on your comment.. What do you mean when you say, that dSPM is "not a plain scaling of the estimates"?
For any *given vertex*, the MNE time course and the dSPM time course (or any other linear inverse time course) are indeed different only by a scale factor. Of course, the MNE and dSPM *spatial maps* are not scaled versions of each other because the multiplier that relates the dSPM estimates to the MNE estimates is different for each vertex (the point of noise normalization being to improve the spatial map).
Also, if the baseline period is used for noise cov estimation, it is not clear to my why post hoc normalization by the baseline standard deviation is different from dSPM (even mathematically)..
Hari
Hari Bharadwaj
PhD Candidate, Biomedical Engineering,
Auditory Neuroscience Laboratory
Boston University, Boston, MA 02215
Martinos Center for Biomedical Imaging,
Massachusetts General Hospital
Charlestown, MA 02129
Just to follow up on your comment.. What do you mean when you say, that dSPM is "not a plain scaling of the estimates"?
yes it is. I wasn't clear. What I meant is that when you change nave you
don't just change the scale of dSPM. At least numerically it is not the case
as confirmed by a tiny experiment.
For any *given vertex*, the MNE time course and the dSPM time course (or any other linear inverse time course) are indeed different only by a scale factor. Of course, the MNE and dSPM *spatial maps* are not scaled versions of each other because the multiplier that relates the dSPM estimates to the MNE estimates is different for each vertex (the point of noise normalization being to improve the spatial map).
yes no confusion here.
Also, if the baseline period is used for noise cov estimation, it is not clear to my why post hoc normalization by the baseline standard deviation is different from dSPM (even mathematically)..
dSPM is not exactly a z-scoring.
if it were the case the std deviation of each time course during
baseline would be exactly 1.
Also when you use a noise cov in dSPM, you often add a regularization
and the inverse code clips the tiny eigenvalues.
Hi Alex,
Thanks for the gist! Just ran it.. The results actually see to suggest
that the two stc (one with the original nave of 55, and the new nave of
10000) are pretty much scaled versions of each other with the scale
factor being exactly what you would expect, namely the ratio of the
sqrt(nave) in the two cases:
See: http://nmr.mgh.harvard.edu/~hari/MNEnotes/dSPM_nave_scaling.pdf
I agree with you that the regularization would change the numerical values
very slightly and hence they won't be *exactly* equal.
Also, I do think dSPM is pretty much z-scoring when you use the baseline
periods to estimate the noise covariance. If w_i is the row of the inverse
operator corresponding to the weights needed to estimate the MNE of source #i, and C is the noise covariance, then the normalization factor used in
dSPM for that source is:
sqrt(w_i*C*w_i.T) (where .T denotes a transpose), which is indeed the
estimated standard deviation of the baseline. The reason that the dSPM
standard deviation is not *exactly* equal to 1 in the baseline is that the
noise-cov is estimated from raw-data samples and scaled by 'nave' = #trials_in_evoked, rather than being estimated from the baseline of the
evoked data.
On the other hand, if you had many datasets/sources and calculated the
baseline standard deviation, then across the datasets/sources you would
have the baseline sample standard deviation be distributed narrowly
around 1. In other words, the dSPM has a "null distribution" that is
mean zero and variance 1, which is what makes it an "SPM".
Thanks for the gist! Just ran it.. The results actually see to suggest
that the two stc (one with the original nave of 55, and the new nave of
10000) are pretty much scaled versions of each other with the scale
factor being exactly what you would expect, namely the ratio of the
sqrt(nave) in the two cases:
See: http://nmr.mgh.harvard.edu/~hari/MNEnotes/dSPM_nave_scaling.pdf
indeed
I agree with you that the regularization would change the numerical values
very slightly and hence they won't be *exactly* equal.
agreed
Also, I do think dSPM is pretty much z-scoring when you use the baseline
periods to estimate the noise covariance. If w_i is the row of the inverse
operator corresponding to the weights needed to estimate the MNE of source #i, and C is the noise covariance, then the normalization factor used in
dSPM for that source is:
sqrt(w_i*C*w_i.T) (where .T denotes a transpose), which is indeed the
estimated standard deviation of the baseline. The reason that the dSPM
standard deviation is not *exactly* equal to 1 in the baseline is that the
noise-cov is estimated from raw-data samples and scaled by 'nave' = #trials_in_evoked, rather than being estimated from the baseline of the
evoked data.
On the other hand, if you had many datasets/sources and calculated the
baseline standard deviation, then across the datasets/sources you would
have the baseline sample standard deviation be distributed narrowly
around 1. In other words, the dSPM has a "null distribution" that is
mean zero and variance 1, which is what makes it an "SPM".
What am I missing?
nothing. This is correct. This makes me think that one should have
a quality insurance routine that checks how much dSPM is an
"SPM" map as you explained. I you have a good suggestion please share.
{kind=link}
{kind=link}
{kind=link}