Hi everyone,
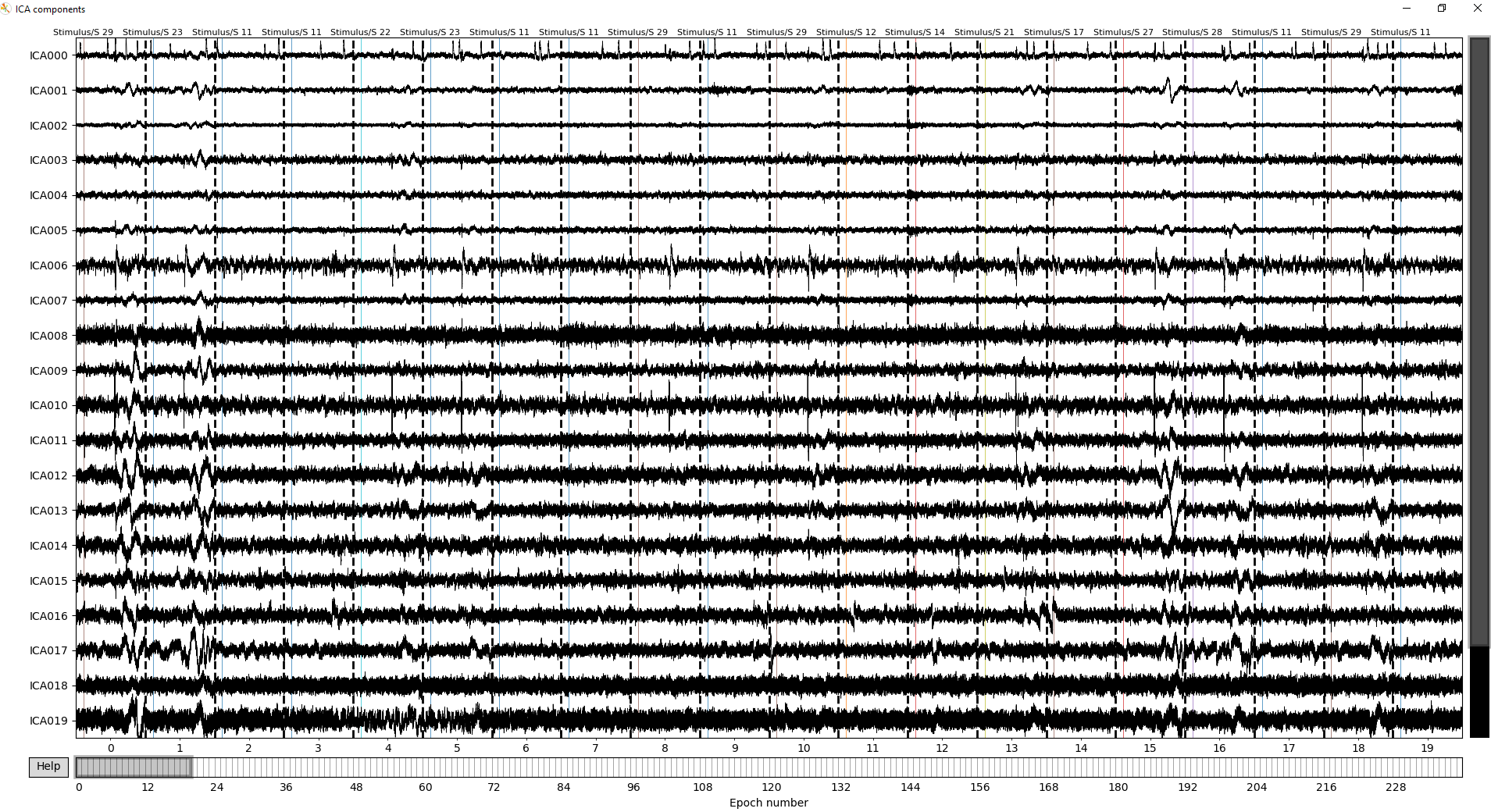
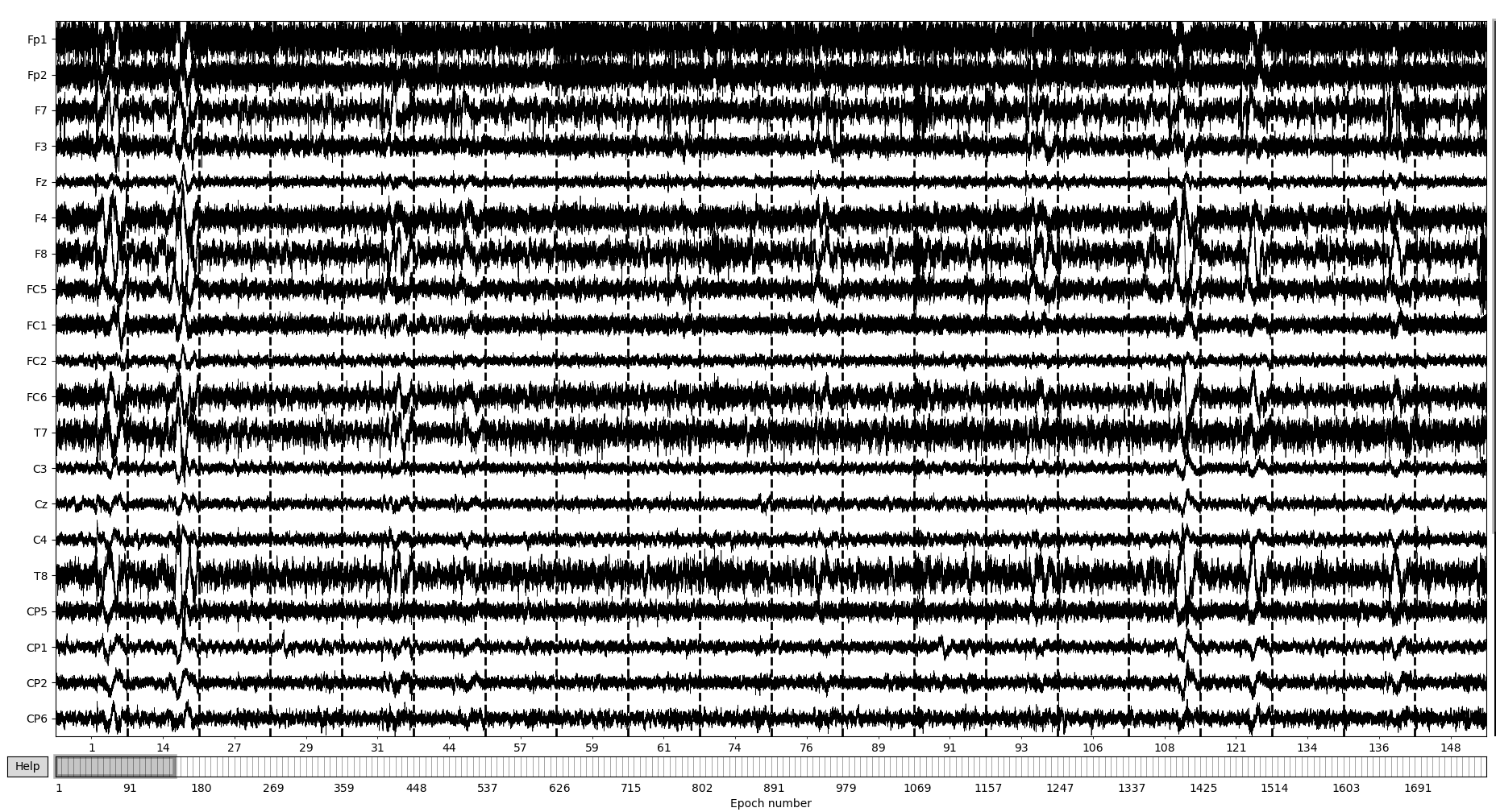
I have an issue with plotting my data. In the beginning of my code my continious data get segmented (flux_eegEpochs). This works fine, I get 240 events, like it should be (see dataepoch.info). If I later one want to plot the data with either reconst_raw.plot() or dataica.plot(), i get the wrong indicies (see dataicaplots).
So the data within the flux_eegEpochs get segmented correctly and dataepoch.info contains all 240 events. Filt_data which is definded as dataepoch.copy() does not include the info over the segments anymore. I have no idea why the segments dont get display correctly in the plot. If you look at the dataicaplot, the indices start with 1 than 14, 27 and so on. Really strange indices that differ from each participants dataset and are supposed to be from 0 to 239
#define functions
def slice(sourcedict, string):
newdict = {}
for key in sourcedict.keys():
if key.startswith(string):
newdict[key] = sourcedict[key]
return newdict
def flux_eegEpochs (raw_load):
#Convert an Annotations object to an Events array
events, event_dict = mne.events_from_annotations(raw_load)
print(event_dict)
print(events[:5])
# Visualize all events
fig = mne.viz.plot_events(events, sfreq=raw_load.info['sfreq'],
first_samp=raw_load.first_samp, event_id=event_dict)
fig.subplots_adjust(right=0.7) # make room for legend
#Create dicionary for trial onset events
on_dict = slice(event_dict, 'Stimulus/S ')
# Epoch data
epochs = mne.Epochs(raw_load,
events,
event_id=on_dict,
tmin=-1,
tmax=8,
detrend=1,
baseline=None,
proj=True,
preload=True)
len(epochs.events)
return epochs
def identify_ica(raw):
""" Use ICA to reject artifacts
"""
# Perform ICA
ica = mne.preprocessing.ICA(
n_components=20, # Number of components to return
max_pca_components=None, # Don't reduce dimensionality too much
random_state=0,
max_iter=800,
verbose='INFO')
ica.fit(raw, reject_by_annotation=True)
# Plot ICA results
ica.plot_components(inst=raw) # Scalp topographies - Click for more info
ica.plot_sources(raw) # Time-courses - click on the ones to exclude
return ica
#Subject Info: (10 & 15 excl. in Rati & Reex, 11 excl. in Reex)
#Subjects included:
#3,4,9,(10),(11),12,13,14,(15),16,17,18,19,20,21,22,23,24,27,28,29,31,32,34,35,
#36,37,38,40,41,42,43,44,45,46,47,48,51,52,53,54,55,56,57,58,59,61
subject = 'sub-29'
session = 'ses-Expo'
bids_root ='C:\\Users\\Admin\\Desktop\\Projekt_Franziska\\Oszillationen\\TF-Analyse\\BIDS'
mne_data_folder=bids_root + '/' + subject + '/' + session + '/' + 'eeg/'
raw_load=mne.io.read_raw_fif(mne_data_folder + subject + '_' + session + '_run01_' + 'data_interpolated.fif', verbose=False)
# Check annotations to see markers
# S 1n for CS- Onset
# S11n for CS- Offset
# S 2n for CS+ Onset
# S22n to CS+ Offset.
# The last number (n) of the marker refers to the ratings (low 1 to high 9)
print(raw_load.annotations)
print(len(raw_load.annotations))
print(set(raw_load.annotations.duration))
print(set(raw_load.annotations.description))
print(raw_load.annotations.onset[0])
dataepoch=flux_eegEpochs (raw_load)
print(dataepoch.info)
filt_data = dataepoch.copy()
filt_data.load_data().filter(l_freq=1., h_freq=None)
raw_ica=identify_ica(filt_data);
# RUN ALL THE ABOVE BEFORE ENTERING ICA VALUES TO EXCLUDE BELOW
raw_ica.exclude = [0,6,10] # indices chosen based on various plots above
reconst_raw = filt_data.copy()
dataica=raw_ica.apply(reconst_raw)
dataica.save(mne_data_folder + subject + '_' + session + '_run01_' + 'data_ica.fif', overwrite=True)
## Check whether ICA worked as expected
reconst_raw.plot()
dataica.plot()


Thanks a lot for your help!!
Best,
Franziska